Туторіал з налаштування Rails-додатків на Amazon EC2 з Chef. Частина 1
Всім привіт! Мене звати Ярослав Безрукавий, я — Ruby/JavaScript розробник в RubyGarage. Цією статтею хочу розпочати цикл туторіалів із розгортання Rails-додатків. Ідея такого туторіалу прийшла до мене тоді, коли я робив перші спроби знайомства із DevOps. Коли я тільки починав, мені складно було зрозуміти, з чого складається процес розгортання додатків, та я ніяк не міг знайти ресурс, де інформація викладалася б зрозумілою мовою для новачків. Іншими словами, я мусив збирати потрібну мені інформацію по частинах, як пазл.
Одним із перших інструментів для розгортання додатків, який я спробував опанувати, був Chef. І це було нелегко. Усі статті про налаштування інфраструктури, що я бачив, розглядали або лише певну частину всього процесу, або примітивні задачі, котрі не мали практичного застосування. Таким чином, щоб отримати повну картину застосування Chef для розгортання Rails-додатків, я повинен був подивитись тисячі джерел та прикладів коду на GitHub.
Тому своєю статтею я хочу допомогти всім початківцям-рубістам, які хочуть опанувати розгортання веб-додатків. Я намагався систематизувати та викласти доступною мовою всі отримані знання. Перед вами — перша частина туторіалу. Усього планується три частини.
Тож давайте налаштуємо наш перший Rails-додаток разом!
З чим доведеться зіткнутися
Якщо ви вирішили налаштувати сервер через підхід, що включає мануальне редагування тексту, переходи між екранами графічного інтерфейсу та періодичне використання інтерфейсу командного рядка, ви можете зіткнутися з такими труднощами:
- Snowflake servers — створення й налаштування ідентичних серверів (наприклад, для staging і production середовища) забирає багато часу, вимагаючи повторення тих самих дій. Це змушує команду розробників зосередитися на вирішенні старих проблем, а не на створенні інновацій.
- Історія змін — ви маєте пам’ятати про всі внесені вами зміни або мати окремий документ, де реєструється стан файлів конфігурації.
- Reverting — повернення сервера до певного стану, наприклад після невдалих змін, забирає багато часу. У критичних випадках краще відтворити сервер з нуля, що поверне нас до першої проблеми.
- Командна робота — великим командам розробників важко керувати серверною інфраструктурою, оскільки зазвичай не існує організованого підходу до конфігурації сервера. Будь-хто може увійти на сервер додатків і внести зміни через консоль. І такі дії здебільшого важко відслідковувати. Це породжує значну кількість конфліктів і помилок.
- Тестування — використання інструментів тестування інфраструктури у такому форматі роботи або обмежене, або неможливе.
Зростання кількості підтримуваних серверів призводить і до пропорційного збільшення цих проблем. Це ускладнює й уповільнює розробку, зменшує якість програмних продуктів та підвищує ймовірність помилок. А в добу хмарної інфраструктури такі помилки неприпустимі.
Цей туторіал складається з трьох частин, які допоможуть вам подивитися на інфраструктуру сервера з іншого боку, а саме — з боку програмного забезпечення.
У першій частині туторіалу ми обговоримо переваги підходу «інфраструктура як код» та розглянемо Сhef — платформу автоматизації, яка реалізує цей підхід. Також розпочнемо опис основної конфігурації для встановлення Rails-додатка на Amazon EC2.
Рішення: інфраструктура як код
Інфраструктура як код (IaC), або програмована інфраструктура, є типом ІТ-інфраструктури, яка дозволить вам автоматично нею керувати й доповнювати, написавши код замість ручного налаштування. Цей код можна написати високорівневою мовою або будь-якою описовою мовою.
З IaC ви не просто пишете скрипти. Він передбачає використання перевірених практик розробки програмного забезпечення, таких як контроль версій, тестування, невеликі розгортання програмного забезпечення, шаблони дизайну тощо.
Передумови
Давайте розглянемо підхід «інфраструктура як код», налаштувавши інфраструктуру для Spree-додатка. Щоб цей додаток функціонував правильно на віртуальному приватному сервері (VPS), потрібне таке програмне забезпечення:
- Ubuntu 16.04 — операційна система;
- Ruby Version Manager (RVM) з Ruby 2.4.2 як стандартне налаштування;
- PostgreSQL 9.6 — реляційна база даних;
- Nginx 1.11.13 — веб-сервер і зворотний проксі-сервер (reverse proxy server);
- Redis 4.0.2 — розподілене сховище пар ключ-значення;
- ImageMagick — інструмент обробки зображень;
- Monit — утиліта для управління й моніторингу систем Unix.
Рішення: Сhef
У цьому туторіалі ми розгорнемо Spree-додаток за допомогою Сhef. Але перш ніж це зробити, слід вивчити основи цього інструменту.
Сhef — потужна платформа автоматизації, яку ви можете використовувати для керування серверами, перетворюючи вашу інфраструктуру на код. Використовуючи Chef, ви можете написати інструкції зі встановлення й налаштування різних пакетів і систем управління пакетами незалежно від операційної системи — у хмарі, локально або змішано. Наприклад, ви можете налаштувати конфігурацію для PostgreSQL. Особливість Chef полягає в тому, що він надає Ruby DSL (предметно-орієнтовану мову програмування) для опису цих інструкцій.
Оскільки Chef часто працює централізовано, центральний сервер Сhef знає, які конфігурації потрібно застосувати до значної кількості інших серверів. Тож, якщо ви оновлюєте конфігурацію, ці зміни застосовуються автоматично до всіх серверів. Таким чином, ви можете зручно керувати інфраструктурою з великою кількістю серверів.
Chef також може працювати в автономній конфігурації (Сhef-solo). У цьому випадку ми використовуємо наше локальне середовище для визначення конфігурації сервера, а потім, за необхідності, вручну застосовуємо такі конфігурації до інших серверів. Це ідеальне рішення для невеликих проектів, усі елементи яких працюють на одному сервері. Тому, щоб допомогти вам краще зрозуміти, як працювати з Сhef, ми наводимо всі приклади в цій статті в автономному режимі (chef-solo). В окремій статті ми обговоримо, як використовувати Сhef для управління інфраструктурою з великою кількістю серверів.
Перш ніж розпочати аналіз того, як використовувати Сhef для налаштування сервера, слід ознайомитись з його ідеологією. Спочатку це може бути заплутаним, але насправді все доволі просто.
Конфігурація для встановлення або налаштування певного компоненту сервера (наприклад, RVM, PostgreSQL, Redis або Monit) називається recipe. Recipes об’єднуються в cookbooks. Один cookbook повинен містити щонайменше один recipe. Тож, якщо у вас є два recipes (один для встановлення RVM на сервері, а другий — для встановлення rubies через RVM), ви можете об’єднати ці два recipes у Ruby cookbook, використовуючи цей cookbook для комплексного встановлення Ruby.
Так само, як Ruby дозволяє виокремити деякі готові рішення в автономні геми для повторного використання, Сhef дозволяє розділити рішення в cookbooks. Для цього ми використовуємо Berksfile, який відіграє для cookbook таку ж роль, як Gemfile для гемів. У Berksfile вам слід визначити cookbooks, від яких залежить ваше налаштування. Таким же чином, як команда bundle install встановлює необхідні геми, Berkshelf встановлює Сhef cookbooks (включаючи конкретні версії), від яких залежить конфігурація вашого сервера.
Припустімо, що у вас є декілька cookbooks, наприклад PostgreSQL та Monit, і ви бажаєте об’єднати їх в один перелік запусків (run list), і щоб PostgreSQL було встановлено на сервер першим, a всі налаштування для моніторингу процесів — пізніше. Ви можете скористатися role для вирішення цього завдання. Role дозволяє вам об’єднати cookbooks, що належать до однієї функції роботи, і встановити суворий порядок виконання recipes. Створена вами role допоможе застосовувати cookbooks до серверів, що мають спеціальні призначення у вашій інфраструктурі. Тож, ви можете поєднати cookbook для встановлення PostgreSQL з recipe налаштування моніторингу PostgreSQL в єдину role у базі даних.
Як правило, коли ми описуємо конфігурацію кожного хоста окремо, ми застосовуємо певний набір cookbooks, roles та інших параметрів. Для цього ми використовуємо node. Node — це будь-яка система (сервер, хмара, віртуальна машина, мережний пристрій або контейнер), якою ви можете управляти за допомогою Chef.
При дотриманні підходу «інфраструктура як код» слід переконатися, що recipes придатні для повторного використання. Наприклад, якщо ви хочете встановити Ruby версію 2.4.1 на одному node та версію 2.5.0 на іншому, ви не хочете писати два окремі recipes для даного завдання. Замість цього ви можете використовувати атрибути (attributes) — параметри у вигляді пар ключ-значення. Використання атрибутів дозволяє налаштувати поведінку recipes. Ми вже згадували про встановлення різних версій того самого пакета, такого як Ruby.
Атрибути, які належать певному environment додатку (staging.app.com, dev.app.com), записуються у директорію environments. Так само атрибути можна визначити на рівні cookbooks, roles та nodes.
Уявіть, що декілька користувачів мають доступ до вашої інфраструктури, і кожен з них має власний набір прав. Кожен користувач має свій унікальний ідентифікатор/ім’я та може отримати доступ до інфраструктури лише за допомогою свого унікального пароля або SSH-ключа. Data_bags можуть допомогти з цим завданням. Data bag ‒ це глобальна змінна, яка містить облікові дані й дозволи користувачів у форматі JSON.
Data bags також придатні для зберігання глобальних змінних, що містять, наприклад, облікові дані або секретні ключі від зовнішніх сервісів. З міркувань безпеки ця інформація має зберігатися виключно в зашифрованому вигляді. Для цього слід використовувати encrypt_data_bag.
Після того, як конфігурація буде готова, потрібно застосувати її до свого сервера. Ви можете це зробити за допомогою knife. Knife — інструмент інтерфейсу командного рядка, що забезпечує інтерфейс взаємодією між локальним сховищем Chef (розміщеним у вашій системі) та віддаленим сервером.
Традиційно цей віддалений сервер буде головним Chef-сервером. Додатковий інструмент ‒ knife solo ‒ дозволяє вам використовувати Сhef в автономному режимі, безпосередньо взаємодіючи із сервером, який ви хочете налаштувати. Більше інформації про knife solo ви можете знайти в репозиторії.
Отже, ми розглянули:
- Recipes;
- Cookbooks;
- Roles;
- Nodes;
- Атрибути (attributes);
- Середовища (environments);
- Data bags;
- Berksfile;
- Knife solo.
Більш детальну інформацію про Сhef можна знайти в його документації.
Тепер час перейти до практичної частини нашої статті, а саме — написання конфігурацій для сервера, де буде розміщено наш Spree-додаток.
Встановлення віртуального приватного сервера (EC2)
Перш за все, вам потрібен VPS, сервер, на якому ви будете розгортати вашу програму. Для цього завдання ми скористаємося AWS EC2 (Amazon Elastic Compute Cloud). EC2 — це веб-служба, яка дозволяє отримувати доступ до обчислювальних ресурсів та налаштовувати їх із мінімальними зусиллями. Ця послуга є частиною інфраструктури Amazon Web Services (AWS).
Встановлення екземпляра EC2 передбачає декілька етапів:
1. Виберіть Amazon Machine Image.
Для нашого додатка Spree виберіть Ubuntu 16.0.

2. Виберіть тип інстансу (instance type).
Визначте, які ресурси матиме ваш віддалений сервер.

3. Налаштуйте групи безпеки (security groups).
Відкрийте

4. Review.
Тепер слід переглянути конфігурацію. Перед запуском інстансу створіть і завантажте ключ spree_dev.pem, щоб можна було отримати доступ до свого сервера за допомогою SSH.
Додайте файл цього ключа до .gitignore:
# .gitignore /spree_dev.pem

Тепер на інформаційній панелі ви можете переглянути інформацію про встановлений інстанс. Наприклад, наш сервер отримав таку загальнодоступну IP-адресу: 18.221.230.71. Ваш сервер отримає іншу адресу. Саме тому в нашому туторіалі там, де вам потрібно використовувати призначену IP-адресу, ми будемо писати YOUR_IP_ADDRESS.
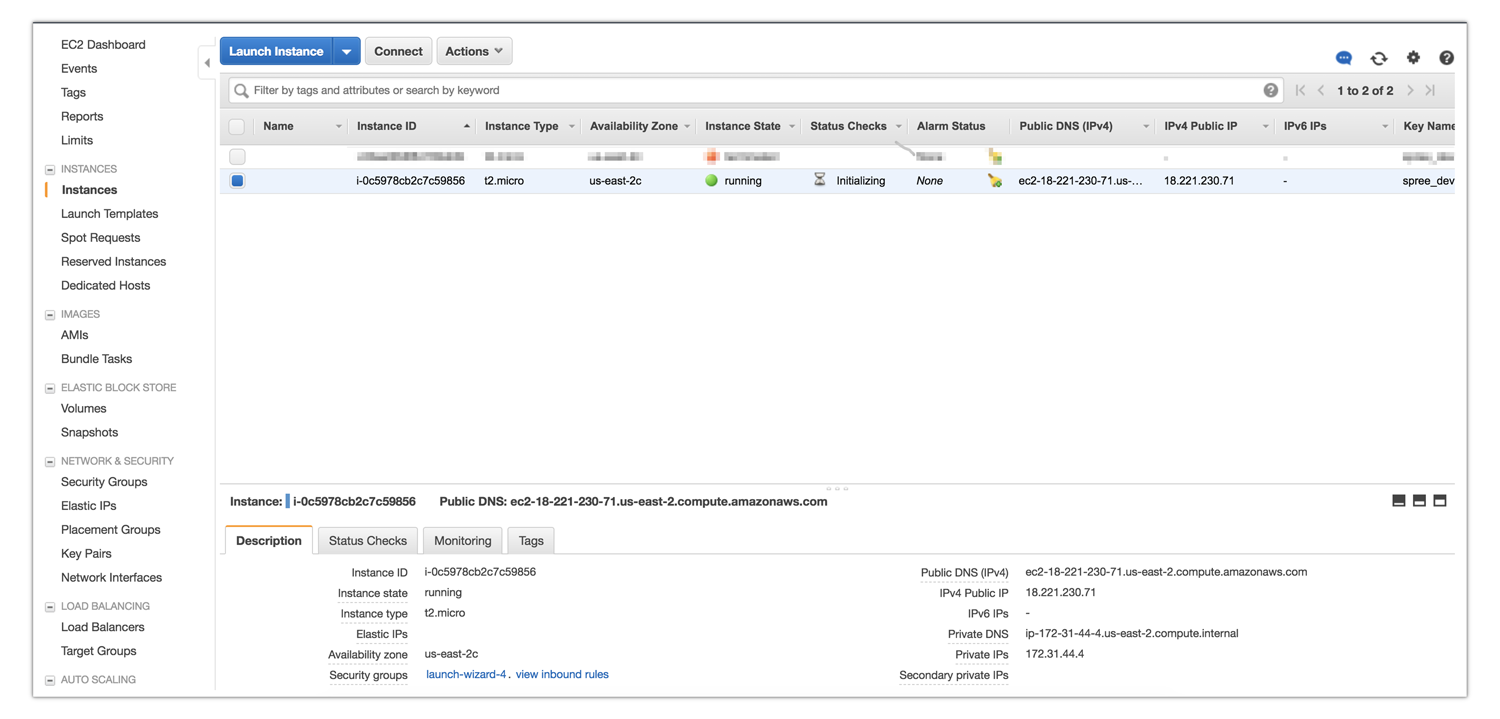
Коли стан інстансу змінюється від ініціалізації до запуску, ви можете авторизуватись через SSH. Потім встановіть права на читання на завантажений вам ключ.
chmod 400 spree_dev.pem
Потім використовуйте цей ключ для підключення через SSH:
ssh -i spree_dev.pem ubuntu@YOUR_IP_ADDRESS
Після того, як ви налаштували інстанс з Сhef, вам більше не потрібно використовувати ключ.
Крок 1. Ініціалізація проекту
Перш за все, треба створити каталог, де ви розмістите конфігурацію для свого сервера у вигляді Сhef-скриптів.
mkdir spree-app && cd spree-app
Потім створіть Gemfile:
touch Gemfile
Цей Gemfile містить геми, потрібні під час роботи з Сhef.
source 'https://rubygems.org' gem 'knife-solo', '~> 0.6.0' gem 'knife-solo_data_bag', '~> 2.1.0' gem 'berkshelf', '~> 6.3.1' gem 'chef', '~> 12.0'
Налаштуйте геми:
bundle install
Після цього можете використовувати команду knife для ініціалізації сховища Chef у поточний каталог.
knife solo init .
Ваш каталог тепер матиме наступну структуру:
. ├─ .chef │ └─ knife.rb ├─ cookbooks ├─ data_bags ├─ environments ├─ nodes ├─ roles ├─ site-cookbooks ├─ Berksfile ├─ Gemfile └─ Gemfile.lock
Ви вже знаєте основні компоненти Сhef. Але додані каталоги містять .chef директорію, де знаходиться файл knife.rb. Ми використовуємо цей файл, щоб вказати інформацію про конфігурацію для knife client. За стандартними налаштуваннями knife client має конфігурацію маршрутів для node, roles тощо. Більш докладну інформацію про конфігурацію knife можна знайти тут.
Тепер ми готові почати описувати конфігурацію нашого сервера.
Крок 2. Data bags
На цьому етапі ми опишемо data bags для користувача (deployer user), від імені якого ми будемо розгортати додаток.
Для цього створіть каталог з назвою users. Цей каталог буде містити файл JSON з конфігураціями для доступу до сервера для кожного користувача.
mkdir data_bags/users touch data_bags/users/deployer.json
Конфігурація для користувача виглядає так:
// data_bags/users/deployer.json
{
"id": "deployer",
"password": "$1$pLkeCZ5O$zKvLFmXDtQhhB3Ur6ual71",
"ssh_keys": [
"SSH_PUBLIC_KEY"
],
"groups": ["sudo" ,"sysadmin", "www-data"],
"shell": "\/bin\/bash"
}
Щоб відрізнити дозволи, операційна система Linux має групи разом з користувачами. Як і користувач, група має права доступу до певних каталогів і файлів. Список груп знаходиться в ключi groups.
Підключимося до сервера через SSH. Для цього скопіюйте вміст public key файлу у термінал.
У Linux ви можете видобути вміст, а потім скопіювати його:
cat ~/.ssh/id_rsa.pub
У macOS ця команда копіює вихідний файл до буфера обміну:
pbcopy < ~/.ssh/id_rsa.pub
Після цього замініть SSH_PUBLIC_KEY на вихідний файл у data_bags / users / deployer.json.
Крок 3. Середовище
Тепер почнемо описувати середовище для налаштування нашого сервера. Давайте розглянемо приклад середовища dev.
Ми створимо файл конфігурації для середовища dev.
touch environments/dev.rb
Тоді нам потрібно вказати атрибути за стандартним налаштуванням.
# environments/dev.rb name 'dev' description 'Development environment' default_attributes( domain_name: 'dev.example.com' )
Крок 4. Node
Далі створимо node для вашого сервера за допомогою вашої унікальної IP-адреси замість YOUR_IP_ADDRESS. У Chef node називаються IP-адреси сервера, до якого будуть застосовуватися описані конфігурації.
Створимо файл конфігурації для node.
touch nodes/YOUR_IP_ADDRESS.json
Потім встановіть атрибути name, environment, run_list та ipaddress.
// nodes/YOUR_IP_ADDRESS.json
{
"name": "spree-app",
"environment": "dev",
"run_list": [],
"automatic": {
"ipaddress": "YOUR_IP_ADDRESS"
}
}
Висновки
У цій частині нашого туторіалу ми розглянули підхід «інфраструктура як код» і платформу автоматизації Сhef, показавши основні складові Chef. Також ми встановили EC2 інстанс та описали для нього базову конфігурацію. У наступній частині туторіалу ми навчимо вас писати власні cookbooks.
Слідкуйте за виходом другої частини нашого туторіалу.
