Де шукати архітектурні тренди та що нас чекає у майбутньому
Я Денис Доронін, Solutions Architect у SoftServe. За 8 років досвіду я не раз переконувався, що архітектор має постійно відстежувати тренди й розуміти, які технологічні рішення з’являються і які проблеми вони здатні розв’язувати. З цим навряд чи хтось посперечається. Але питання в тому, звідки дізнаватися ці тренди.
Один зі способів — це вивчати техрадари. Нижче я розкажу, що це, чим може бути корисне і як ним користуватися.
Що таке TechRadar
Це уніфікований формат подачі трендів, який використовують різні компанії. Кожна з них проводить власне дослідження серед експертів відповідних доменів. Тому одразу застерігаю, що потрібно ретельно обирати джерело інформації. У цій статті я буду орієнтуватися на останній радар ThoughtWorks за жовтень
Радар зазвичай подають у формі круга, розділеного на чотири квадранти: техніки — містить ключові техніки та архітектурні практики, саме на цю секцію ми й будемо орієнтуватися, коли розглядатимемо архітектурні тренди, платформи, інструменти та мови, фреймворки.
Цей загальний круг розшаровується ще на чотири кола:
- Adopt (переймай) — новинки, які рекомендують використовувати.
- Trial (розглянь) — новинки, які уже продемонстрували свою ефективність і варті уваги, хоч ще й не стали популярними.
- Assess (оціни) — багатообіцяльні новинки, які, утім, потребують більше випробувань і досліджень і будуть поки що використовуватися у прототипах.
- Hold (утримайся) — те, що є або ще мало вивченим, або уже застарілим.
У центрі радара — коло Adopt. Що далі від нього містяться продукти чи концепції, то менш вартими уваги вони є.
Ось який це має вигляд (клікніть для збільшення зображення):
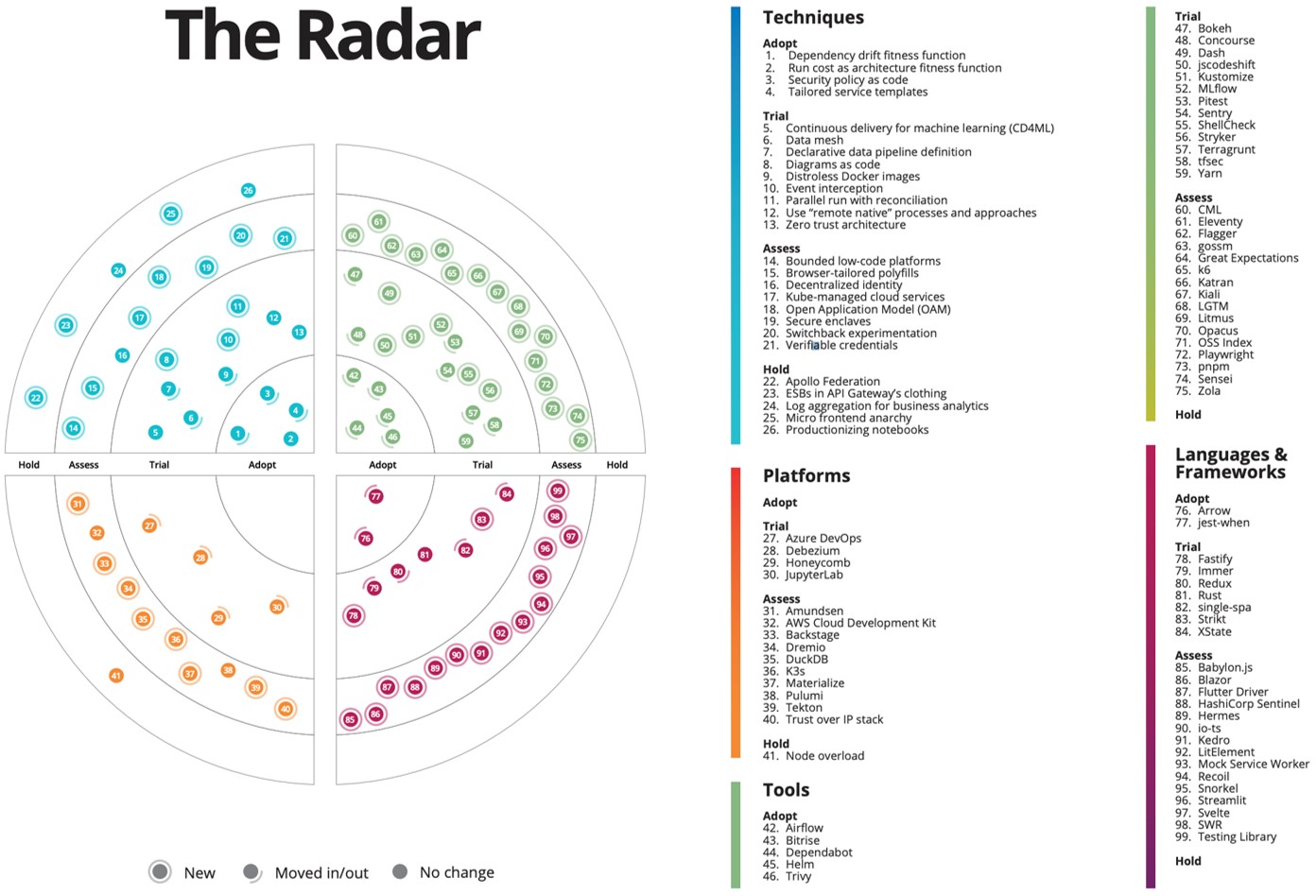
Оновлюється радар приблизно раз у квартал, тому можемо вважати, що інформація в ньому є актуальною. Як я уже згадував, для цього матеріалу використовую радар від ThoughtWorks.
Такі тренди в архітектурі я виділив з його допомогою.
- Тренди, які варто перейняти:
- Security Policy as a Code;
- APIs as a product.
- Тренди, які варто розглянути:
- Continuous delivery for ML;
- Data Mesh;
- Diagram as a code.
- Тренди, які варто оцінити: Kube-managed cloud services.
- Тренди, від яких варто утриматися: Micro frontend anarchy.
Security policy as a code
Радар пропонує нам цю техніку як таку, що вже достатньо перевірена і варта уваги в роботі. Її суть у тому, що всі політики безпеки стають частиною код-бази. Під політиками безпеки маємо на увазі правила доступу до ресурсів і нетворкінгу — які відділи проєктів мають ті чи інші доступи. Згідно із запропонованим підходом, ми переводимо їх у лінії поведінки та конфігурації та накладаємо на них контроль-версії. Це дозволяє контролювати політику безпеки: що ми релізимо, а що ні, як ми її тестуємо, як накладаємо на наш процес CI/CD, як оцінюємо, як хочемо її розвивати та поліпшувати.
 Скетч архітектури Security policy as a code
Скетч архітектури Security policy as a code
Етап 1. Розробка політики безпеки та контроль її версій:
- Розробник створює рішення, робить конфігурацію, сабмітить її в репозиторій, створює політику безпеки та завантажує її на репозиторій.
- Починається CI/CD-процес.
Етап 2. Робота в Security Policy Control Layer:
- На цьому рівні у нас є багато можливих рішень, але я обмежився двома — Open Policy Agent та ISTIO. Перший варіант уже добре відомий серед продуктів для контролю політики безпеки, а другий належить до категорії Service Mesh. Окрім того, за належної конфігурації ISTIO теж уже проявив себе як ефективний продукт для цих цілей.
- За допомогою обраного рішення застосувати створену політику безпеки до проєкту, який має певні модулі, сервіси.
APIs as a product
Цей тренд — один із найпопулярніших серед корпорацій, оскільки роками вони розробляли власні рішення для різних задач. Відповідно в одній такій компанії може бути до сотні дрібних застосунків, що певним чином взаємодіють. Стало зрозуміло, що менеджити потрібно не лише самі ці продукти, а й API — потрібна певна абстракція над API-рівнем, яка виступатиме окремим продуктом. Тож виникають додаткові питання: для кого ми це робимо і кому це потрібно? Як перейти від парадигми, коли наш UI просто викликає API і все, до роботи з API як окремим продуктом?

Таким чином у сфері API ми рухаємося до product orientation парадигми. Ось який це має вигляд з позиції архітектури:
- Рівень API CI/CD — API стає частиною коду, як і та код-база, що надає функціональну можливість для його роботи, тому його теж можна піддати контролю версії.
- Відбувається контроль API як продукту. Тут я вибрав для розгляду два вирішення, які нині популярні й добре розвинуті на ринку — apigee та MuleSoft. Їх не можна назвати взаємозамінними, бо хоч і є категорія використання, для якої вони обидва підходять, але все-таки загалом ці продукти займають окремі ніші.
- Якщо побудуємо API як продукт, отримаємо такі переваги:
- здатність оперувати специфікаціями та продуктами, тобто здатність вирішувати, кому який продукт віддавати. Іншими словами, щойно ми отримуємо API-менеджмент, можемо контролювати квоти: що станеться, якщо клієнт викличе API більше разів, ніж ми розраховували; блокування доступу чи просто трохи більший рахунок за використання API тощо;
- підвищення безпеки, оскільки ми додаємо ще один рівень абстракції між реальним API і тим, який віддаємо в користування клієнту (за допомогою apigee отримаємо додаткове проксі між реальним сервісом і його споживачем).
- Віддаємо API тим, хто буде його використовувати, тобто зовнішнім і внутрішнім сервісам, розробникам і будь-яким іншим можливим користувачам.
Continuous Delivery for ML
Хоч назва цього тренду і звучить захопливо, насправді це просто модифікація пайплайнів і процесів, які уже активно використовуються. Утім вона ще не повністю завершена, тому радар поки що висвітлює її лише на етапі Trial.
Чому взагалі почали задумуватися про CD саме для машинного навчання?
У машинному навчанні ми не маємо єдиної код-бази — зазвичай це комбінація коду і даних моделі. У нас є багато рішень для роботи з моделями, і головне питання — як модель виконує те чи інше завдання. Візьмімо, наприклад, ту, яку ми тренували для розпізнавання певних об’єктів на фото. Одна її версія добре розпізнає людей, а інша — собак, але коли ми намагаємося їх об’єднати, щоб отримати таку, яка ефективно розпізнаватиме і людей, і собак, у нас виникають труднощі й доводиться зберігати обидві версії.
Саме тут і з’являється теорія безперервної доставки для машинного навчання, яка каже нам, що, окрім різних версій коду, потрібно зберігати й різні версії моделі, щоб мати змогу їх згодом протестувати, перевірити, мати контроль над розгортанням — і отримати всі переваги цього підходу.
 Референс архітектури
Референс архітектури
Скетч архітектури цієї концепції:
- Створюється і навчається модель, що є набором коду і даних.
- Модель потрапляє у репозиторій (тут може виникнути питання, чи варто дані нашої моделі версіонувати у вигляді репозиторію, чи в цьому разі добре працюватиме і база даних, яка теж чудово підтримує версійність).
- Беремо код-базу і модель даних і за допомогою CI/CD розгортаємо в систему та отримуємо додаткові переваги й можливості від машинного навчання.
Data Mesh
Data Mesh — одна із найсвіжіших тенденцій в архітектурі IT, тому ми ще не дуже багато про неї знаємо, а радар включає її в групу новинок, які варто розглянути. Мушу визнати, що цей тренд є ще більш заплутаним, ніж попередній, і самі творці техрадара не надто багато уваги приділяють його конкретизації, тому спробуймо розібратися самі.
Data Mesh — це новий підхід до володіння даними, і ось його чотири головні принципи:
- Доменна орієнтованість на децентралізацію володіння даними та архітектури.
- Доменна орієнтованість на дані як на продукт. Тут можемо пригадати один із трендів, які ми обговорювали раніше, — API as a product, оскільки доступ до даних відбувається через API-прошарок.
- Автоматизованість даних у системі для пошуку й роботи з ними.
- Належний контроль доступів, їхня передача та сумісність різних систем.
Ці принципи особливо важливі для великих компаній, які можуть роками чи десятиліттями збирати та зберігати дані, котрі навіть не використовуються. Тільки недавно — близько десяти років тому — вони стали задумуватися над тим, яку ж користь їм приносять усі ті збережені дані. І набули популярності такі явища, як Big Data, аналітика, і останній тренд у цій сфері — Data Mesh. Він є актуальним, тому що недостатньо просто аналізувати дані, їх треба іще відкрити для використання іншим підрозділам у межах компанії.
Data Mesh якраз пропонує зробити дані відкритими й цим розв’язує проблему великих компаній: окремі відділи чи навіть індивідуальні працівники володіють певними даними, про які ніхто навіть не здогадується, коли вони можуть стати в пригоді.
Утім не все так просто, оскільки сьогодні є різниця між безкоштовними та комерційними рішеннями, адже можливості перших значно обмежені. Однак навіть їх буде достатньо, щоб спробувати парадигму Data Mesh.
 Референс архітектури
Референс архітектури
Архітектура Data Mesh складна, але спробуймо розібратися:
- Зовнішні елементи — набір продуктів, у яких є дані (які можуть як генеруватися, так і використовуватися цими продуктами). Наше завдання — об’єднати це все у Data Mesh, тобто надати можливість під’єднуватися до цих даних, взаємодіяти з ними та розв’язувати певні задачі, використовуючи, наприклад, API-прошарок.
- Ці всі дані поміщаємо у сховище, де вони й будуть зберігатися, сортуватися і розподілятися на кілька різних сетів даних. Які можуть бути ізольованими чи отримуватися в процесі вивчення даних і їхньої анонімізації.
- Надаємо доступи до усіх чи окремих сетів даних, і дані використовуються з різною метою.
Diagram as a code
Сама ідея — проста. Вона полягає в тому, щоб замість створення діаграми вручну, малюючи коло за колом і стрілку за стрілкою, автоматизувати цей процес за допомогою коду. В результаті, окрім того, що ми отримуємо автоматично створені діаграми, ми ще й можемо зберігати їх у вигляді коду.
Ось продукти, які можна для цього використовувати:
Нині у розпалі дискусія про те, чи варто всі діаграми переводити у формат коду, чи деякі треба залишити для ручної роботи. Для мене найкраще працює варіант, коли спершу вручну створюю діаграму і переконуюся, що вона працює належним чином, тільки тоді переводжу все в код. Іншими словами, я використовую концепцію діаграми як коду не як інструмент, що допомагає мені створити архітектуру з нуля, а як фінальну частину роботи, коли закінчую свою документацію і готуюся показати її клієнту.

Архітектура цієї концепції досить проста:
- У нас є артефакт — діаграма у форматі коду, псевдокоду, xml, Python script тощо.
- Цей артефакт зберігається у репозиторії.
- За потреби ми його дістаємо й генеруємо діаграму стільки разів і з такими змінами, як нам потрібно.
Наведемо приклад використання концепції діаграми у формі коду, коли нам потрібно згенерувати документацію для SDK. Ця документація міститиме інформацію про те, як ми SDK використовуємо, відповідно, з кожною версією SDK виникатиме потреба змінити й діаграму. Діаграма у формі коду значно полегшує завдання, оскільки ви фіналізуєте своє бачення для першого релізу, а для всіх наступних просто змінюєте код і генеруєте діаграму автоматично. Цей підхід також стане в пригоді, якщо архітектура значно змінюватиметься з кожним релізом, бо ви матимете змогу контролювати та порівнювати версії коду та діаграми. А ще цим можна буде скористатися, якщо виникне потреба показати зміни клієнту чи організувати навчання новачків на проєкті.
Kube-managed cloud services
Цю концепцію творці техрадара розмістили ближче до дальнього краю кола (Assess), що означає, що це ще зовсім нова тенденція в DevOps, і випадків її успішного впровадження поки було небагато.
Нині є тенденція, що cloud-провайдери починають підтримувати API у стилі Kubernetes, тобто вони можуть прямо інтегруватися з Kube через custom resource definitions (CRDs). І тут виникає проблема: коли ми починаємо будувати Kube-кластер, нам усе одно доведеться працювати із зовнішніми сервісами та менеджмент-сервісами того чи іншого cloud-провайдера. Відповідно, наш процес переведення конфігурації в код трохи ускладнюється, бо ми повинні окремо писати конфігурації для Kube і для менеджмент-сервісу в хмарі.
Kube-managed cloud services пропонують такий спосіб розв’язання цієї проблеми: cloud-сервіси стають частиною Kube, і ми отримуємо можливість внести це в нашу інфраструктуру та її опис. Ось конкретні рішення для головних платформ:
- ACK для AWS;
- Azure Service Operator для Azure;
- Config Connectors для GCP.
Переваги від цього очевидні: можемо все менеджити з Kubernetes, маючи єдиний кластер, єдиний опис ресурсів і єдиний метод їх розгортання. Утім із цієї переваги виростає помітний недолік — ми стаємо занадто залежними від Kubernetes, що може зрештою стати проблемою в деяких випадках.

І ось який вигляд має архітектура цієї концепції:
- Працюємо за звичайним процесом CI/CD з контролем версії.
- Процес відбувається через Kubernetes. Тут, до речі, нам корисно буде згадати про тренд, який ми обговорювали раніше, — Security as a code, бо ми можемо ефективно використовувати Open Policy Agent для контролю наших конфігурацій, аби перед розгортанням переконатися, що фінальний варіант відповідає вимогам нашої інфраструктури.
- За допомогою якогось з уже згаданих сервісів — AWS, Azure Service Operator чи Config Connector, розгортаємо результат у відповідну хмару.
Micro frontend anarchy
Це останній тренд, про який зауважу. На відміну від технологій, які ми розглянули вище, від використання мікрофронтендів автори техрадара радять утриматися, бо з часу виникнення цієї технології у 2016 році, вона частіше використовується неправильно, ніж успішно.
Мікрофронтенд — це існування кількох вбудованих віджетів — різних джерел даних, сервісів і навіть продуктів різних провайдерів — у межах однієї вебсторінки. Таким чином ми можемо мати на одній сторінці програми з різними фронтенд-фреймворками, наприклад React.js і Angular. Звичайно, це не проблема, якщо використовувати це як перехідний стан, коли рухаємося від одного фреймворку до іншого, або ж якщо застосовуємо багато зовнішніх сервісів, на чию поведінку не можемо вплинути. Однак в інших ситуаціях, на думку ThoughtWorks, така поведінка з мікрофронтендами спричиняє хаос і замість того, щоб допомагати в роботі, все заплутує та ускладнює.

Ось як я це бачу з позиції архітектури:
- Ми маємо сторінку з кількома програмами, що їй підпорядковуються.
- Ці програми викликають API з наших внутрішніх і зовнішніх сервісів.
- Проблема виникає тоді, коли один API викликають відразу кілька різних мікрофронтендів, написаних на різних технологіях, та ще й на різних версіях. Тоді складно передбачити поведінку сторінки у різних браузерах та на різних девайсах.
Безконтрольне поєднання фронтендів точно не сприятиме ефективності, але я все-таки вважаю, що повністю відмовлятися від цього підходу не варто, треба просто використовувати його з подвійною обережністю.
Підсумовуючи, раджу досліджувати різні джерела інформації про тренди, зокрема техрадари різних авторів: вивчати нові тренди, порівнювати інформацію і робити власні висновки. Однак головне — розуміти, що технології роблять не заради технологій, а щоб ефективно розв’язувати конкретну задачу. Відповідно, обираючи рішення для проєкту, орієнтуйтеся насамперед на результат, який від вас очікують, і обирайте той стек технологій, який допоможе швидше та простіше його досягти.
